Skip to content
首页
数据治理
大数据
Flink
Hive
编程
观点
Menu
首页
数据治理
大数据
Flink
Hive
编程
观点
Search
Close
Search
[rank_math_breadcrumb]
常用算法 – Trie 树
KAMI
2024-10-25
11:04
大数据
暂无评论
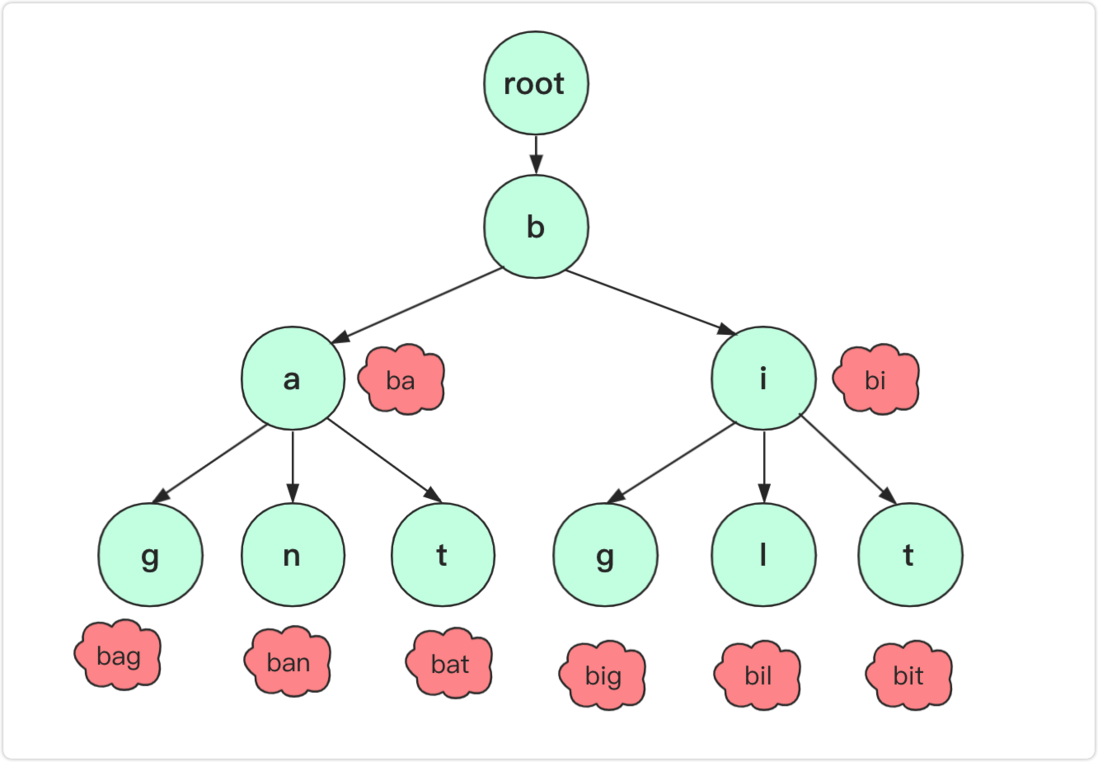
Trie 树
对于字典树,有三个重要性质:
根节点不包含字符,除了根节点每个节点都只包含一个字符。root节点不含字符这样做的目的是为了能够包括所有字符串。
从根节点到某一个节点,路过字符串起来就是该节点对应的字符串。
每个节点的子节点字符不同,也就是找到对应单词、字符是唯一的。
KAMI
数据挖掘研究员,专注分享数据领域的技术和业务,以及逻辑、思维和方法论
Prev
前一篇
常用算法 – SkipList
后一篇
常用算法 – LZ77 / LZ78 / Snappy / LZSS
Next
发表回复
取消回复
要发表评论,您必须先
登录
。
文章结构
相关文章
搭建本地知识库问答系统
KAMI
2024-12-29
没有评论
原理 – MapReduce
KAMI
2024-10-26
没有评论
常用算法 – Bitmap
KAMI
2024-10-25
没有评论
数据订阅
KAMI
2024-10-25
没有评论
数据时间
KAMI
2024-10-25
没有评论
数据接口
KAMI
2024-10-25
没有评论
标签
Flink
(2)
Hadoop
(1)
Hive
(2)
Java
(9)
大数据
(4)
实时
(1)
开发
(24)
数据治理
(5)
方法论
(1)
分类
大数据
(27)
Hive
(4)
工具
(4)
数据治理
(7)
未分类
(1)
编程
(29)
观点
(9)
随记
(20)