MapReduce框架通常由三个操作(或步骤)组成:
- Map:每个工作节点将 map 函数应用于本地数据,并将输出写入临时存储。主节点确保仅处理冗余输入数据的一个副本。
- Shuffle:工作节点根据输出键(由 map 函数生成)重新分配数据,对数据映射排序、分组、拷贝,目的是属于一个键的所有数据都位于同一个工作节点上。
- Reduce:工作节点现在并行处理每个键的每组输出数据。
MapReduce 流程图:
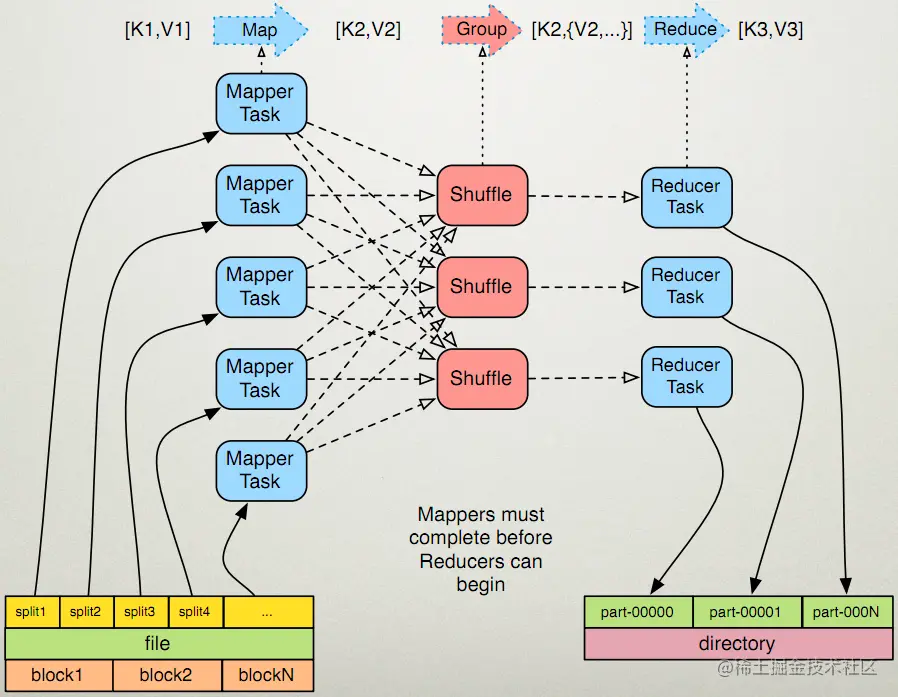
MapReduce 允许分布式运行 Map 操作,只要每个 Map 操作独立于其他 Map 操作就可以并行执行。
另一种更详细的,将 MapReduce 分为5个步骤的理解是:
- Prepare the Map() input:MapReduce 框架先指定 Map 处理器,然后给其分配将要处理的输入数据 — 键值对 K1,并为该处理器提供与该键值相关的所有输入数据;
- Run the user-provided Map() code:Map() 在 K1 键值对上运行一次,生成由 K2 指定的键值对的输出;
- Shuffle the Map output to the Reduce processors:将先前生成的 K2 键值对,根据『键』是否相同移至相同的工作节点;
- Run the user-provided Reduce() code:对于每个工作节点上的 K2 键值对进行 Reduce() 操作;
- Produce the final output:MapReduce 框架收集所有 Reduce 输出,并按 K2 对其进行排序以产生最终结果进行输出。

实际生产环境中,数据很有可能是分散在各个服务器上,对于原先的大数据处理方法,则是将数据发送至代码所在的地方进行处理,这样非常低效且占用了大量的带宽,为应对这种情况,MapReduce 框架的处理方法是,将 Map() 操作或者 Reduce() 发送至数据所在的服务器上,以『移动计算替代移动数据』,来加速整个框架的运行速度,大多数计算都发生在具有本地磁盘上数据的节点上,从而减少了网络流量。
Mapper
一个 Map 函数就是对一些独立元素组成的概念上的列表的每一个元素进行指定的操作,所以每个元素都是被独立操作的,而原始列表没有被更改,因为这里创建了一个新的列表来保存新的答案。这就是说,Map 操作是可以高度并行的
MapReduce 框架的 Map 和 Reduce 函数都是根据 (key, value) 形式的数据结构定义的。 Map 在一个数据域(Data Domain)中获取一个键值对,然后返回一个键值对的列表:
Map(k1,v1) → list(k2,v2)
复制代码
Map 函数会被并行调用,应用于输入数据集中的每个键值对(keyed by K1)。然后每个调用返回一个键值对(keyed by K2)列表。之后,MapReduce 框架从所有列表中收集具有相同 key(这里是 k2)的所有键值对,并将它们组合在一起,为每个 key 创建一个组。
Reducer
而 Reduce 是对一个列表的元素进行适当的合并。虽然不如 Map 函数那么并行,但是因为化简总是有一个简单的答案,大规模的运算相对独立,所以化简函数在高度并行环境下也很有用。Reduce 函数并行应用于每个组,从而在同一个数据域中生成一组值:
Reduce(k2, list (v2)) → list(v3)
复制代码
Reduce 端接收到不同任务传来的有序数据组。此时 Reduce() 会根据程序猿编写的代码逻辑进行相应的 reduce 操作,例如根据同一个键值对进行计数加和等。如果 Reduce 端接受的数据量相当小,则直接存储在内存中,如果数据量超过了该缓冲区大小的一定比例,则对数据合并后溢写到磁盘中。
Partitioner
前面提到过,Map 阶段有一个分割成组的操作,这个划分数据的过程就是 Partition,而负责分区的 java 类就是 Partitioner。
Partitioner 组件可以让 Map 对 Key 进行分区,从而将不同分区的 Key 交由不同的 Reduce 处理,由此,Partitioner 数量等同于 Reducer 的数量,一个 Partitioner 对应一个 Reduce 作业,可认为其就是 Reduce 的输入分片,可根据实际业务情况编程控制,提高 Reduce 效率或进行负载均衡。MapReduce 的内置分区是HashPartition。
具有多个分割总是有好处的,因为与处理整个输入所花费的时间相比,处理分割所花费的时间很短。当分割较小时,可以更好的处理负载平衡,但是分割也不宜太小,如果过小,则会使得管理拆分和任务加载的时间在总运行时间中占过高的比重。
下图是 map 任务和 reduce 任务的示意图:

